
A picture can convey an excellent deal, but it could even be marred by varied points resembling movement blur, haze, noise, and low dynamic vary. These issues, generally known as degradations in low-level pc imaginative and prescient, can come up from tough environmental circumstances like warmth or rain or from limitations of the digicam itself. Picture restoration represents a core problem in pc imaginative and prescient, striving to get better a high-quality, clear picture from one exhibiting such degradations. Picture restoration is complicated as a result of there may be a number of options for restoring any given picture. Some approaches goal particular degradations, resembling lowering noise or eradicating blur or haze.
Whereas these strategies can yield good outcomes for explicit points, they usually battle to generalize throughout various kinds of degradation. Many frameworks make use of a generic neural community for a variety of picture restoration duties, however these networks are every educated individually. The necessity for various fashions for every sort of degradation makes this strategy computationally costly and time-consuming, resulting in a concentrate on All-In-One restoration fashions in latest developments. These fashions make the most of a single, deep blind restoration mannequin that addresses a number of ranges and varieties of degradation, usually using degradation-specific prompts or steerage vectors to boost efficiency. Though All-In-One fashions usually present promising outcomes, they nonetheless face challenges with inverse issues.
InstructIR represents a groundbreaking strategy within the discipline, being the primary picture restoration framework designed to information the restoration mannequin by human-written directions. It may possibly course of pure language prompts to get better high-quality photos from degraded ones, contemplating varied degradation sorts. InstructIR units a brand new normal in efficiency for a broad spectrum of picture restoration duties, together with deraining, denoising, dehazing, deblurring, and enhancing low-light photos.
This text goals to cowl the InstructIR framework in depth, and we discover the mechanism, the methodology, the structure of the framework together with its comparability with state-of-the-art picture and video technology frameworks. So let’s get began.
Picture restoration is a elementary drawback in pc imaginative and prescient because it goals to get better a high-quality clear picture from a picture that demonstrates degradations. In low-level pc imaginative and prescient, Degradations is a time period used to symbolize disagreeable results noticed inside a picture like movement blur, haze, noise, low dynamic vary, and extra. The rationale why picture restoration is a fancy inverse problem is as a result of there may be a number of completely different options for restoring any picture. Some frameworks concentrate on particular degradations like lowering occasion noise or denoising the picture, whereas others would possibly focus extra on eradicating blur or deblurring, or clearing haze or dehazing.
Current deep studying strategies have displayed stronger and extra constant efficiency when in comparison with conventional picture restoration strategies. These deep studying picture restoration fashions suggest to make use of neural networks based mostly on Transformers and Convolutional Neural Networks. These fashions might be educated independently for numerous picture restoration duties, and so they additionally possess the flexibility to seize native and international characteristic interactions, and improve them, leading to passable and constant efficiency. Though a few of these strategies may match adequately for particular varieties of degradation, they usually don’t extrapolate properly to various kinds of degradation. Moreover, while many current frameworks use the identical neural community for a large number of picture restoration duties, each neural community formulation is educated individually. Therefore, it’s apparent that using a separate neural mannequin for each conceivable degradation is impracticable and time consuming, which is why latest picture restoration frameworks have targeting All-In-One restoration proxies.
All-In-One or Multi-degradation or Multi-task picture restoration fashions are gaining recognition within the pc imaginative and prescient discipline since they’re able to restoring a number of sorts and ranges of degradations in a picture with out the necessity of coaching the fashions independently for every degradation. All-In-One picture restoration fashions use a single deep blind picture restoration mannequin to deal with differing kinds and ranges of picture degradation. Totally different All-In-One fashions implement completely different approaches to information the blind mannequin to revive the degraded picture, for instance, an auxiliary mannequin to categorise the degradation or multi-dimensional steerage vectors or prompts to assist the mannequin restore various kinds of degradation inside a picture.
With that being mentioned, we arrive at text-based picture manipulation because it has been carried out by a number of frameworks prior to now few years for textual content to picture technology, and text-based picture enhancing duties. These fashions usually make the most of textual content prompts to explain actions or photos together with diffusion-based fashions to generate the corresponding photos. The primary inspiration for the InstructIR framework is the InstructPix2Pix framework that permits the mannequin to edit the picture utilizing person directions that instructs the mannequin on what motion to carry out as a substitute of textual content labels, descriptions, or captions of the enter picture. In consequence, customers can use pure written texts to instruct the mannequin on what motion to carry out with out the necessity of offering pattern photos or further picture descriptions.
Constructing on these fundamentals, the InstructIR framework is the primary ever pc imaginative and prescient mannequin that employs human-written directions to realize picture restoration and remedy inverse issues. For pure language prompts, the InstructIR mannequin can get better high-quality photos from their degraded counterparts and in addition takes into consideration a number of degradation sorts. The InstructIR framework is ready to ship state-of-the-art efficiency on a big selection of picture restoration duties together with picture deraining, denoising, dehazing, deblurring, and low-light picture enhancement. In distinction to current works that obtain picture restoration utilizing realized steerage vectors or immediate embeddings, the InstructIR framework employs uncooked person prompts in textual content kind. The InstructIR framework is ready to generalize to restoring photos utilizing human written directions, and the one all-in-one mannequin carried out by InstructIR covers extra restoration duties than earlier fashions. The next determine demonstrates the various restoration samples of the InstructIR framework.
InstructIR : Methodology and Structure
At its core, the InstructIR framework consists of a textual content encoder and a picture mannequin. The mannequin makes use of the NAFNet framework, an environment friendly picture restoration mannequin that follows a U-Internet structure because the picture mannequin. Moreover, the mannequin implements job routing strategies to study a number of duties utilizing a single mannequin efficiently. The next determine illustrates the coaching and analysis strategy for the InstructIR framework.

Drawing inspiration from the InstructPix2Pix mannequin, the InstructIR framework adopts human written directions because the management mechanism since there is no such thing as a want for the person to supply further info. These directions provide an expressive and clear method to work together permitting customers to level out the precise location and kind of degradation within the picture. Moreover, utilizing person prompts as a substitute of mounted degradation particular prompts enhances the usability and purposes of the mannequin because it may also be utilized by customers who lack the required area experience. To equip the InstructIR framework with the potential of understanding numerous prompts, the mannequin makes use of GPT-4, a big language mannequin to create numerous requests, with ambiguous and unclear prompts eliminated after a filtering course of.
Textual content Encoder
A textual content encoder is utilized by language fashions to map the person prompts to a textual content embedding or a set measurement vector illustration. Historically, the textual content encoder of a CLIP mannequin is a crucial part for textual content based mostly picture technology, and textual content based mostly picture manipulation fashions to encode person prompts because the CLIP framework excels in visible prompts. Nevertheless, a majority of instances, person prompts for degradation characteristic little to no visible content material, due to this fact, rendering the big CLIP encoders ineffective for such duties since it is going to hamper the effectivity considerably. To deal with this problem, the InstructIR framework opts for a text-based sentence encoder that’s educated to encode sentences in a significant embedding house. Sentence encoders are pre-trained on hundreds of thousands of examples and but, are compact and environment friendly compared to conventional CLIP-based textual content encoders whereas being able to encode the semantics of numerous person prompts.
Textual content Steering
A significant side of the InstructIR framework is the implementation of the encoded instruction as a management mechanism for the picture mannequin. Constructing on this, and impressed in job routing for a lot of job studying, the InstructIR framework proposes an Instruction Building Block or ICB to allow task-specific transformations inside the mannequin. Standard job routing applies task-specific binary masks to channel options. Nevertheless, because the InstructIR framework doesn’t know the degradation, this system isn’t carried out straight. Moreover, for picture options and the encoded directions, the InstructIR framework applies job routing, and produces the masks utilizing a linear-layer activated utilizing the Sigmoid perform to supply a set of weights relying on the textual content embeddings, thus acquiring a c-dimensional per channel binary masks. The mannequin additional enhances the conditioned options utilizing a NAFBlock, and makes use of the NAFBlock and Instruction Conditioned Block to situation the options at each the encoder block and the decoder block.
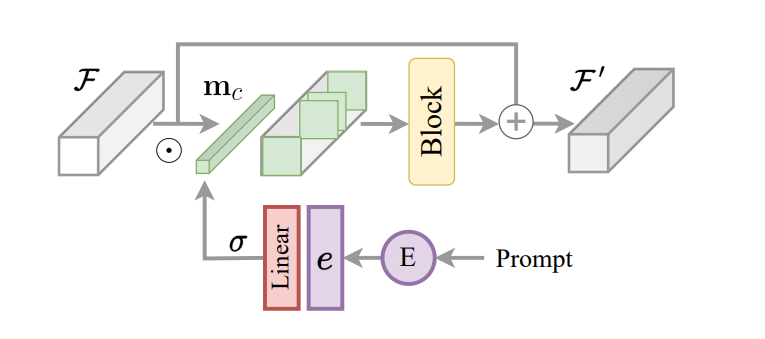
Though the InstructIR framework doesn’t situation the neural community filters explicitly, the masks facilitates the mannequin to pick the channels most related on the idea of the picture instruction and knowledge.
InstructIR: Implementation and Outcomes
The InstructIR mannequin is end-to-end trainable, and the picture mannequin doesn’t require pre-training. It is just the textual content embedding projections and classification head that must be educated. The textual content encoder is initialized utilizing a BGE encoder, a BERT-like encoder that’s pre-trained on an enormous quantity of supervised and unsupervised knowledge for generic function sentence encoding. The InstructIR framework makes use of the NAFNet mannequin as picture mannequin, and the structure of NAFNet consists of a 4 degree encoder decoder with various variety of blocks at every degree. The mannequin additionally provides 4 center blocks between the encoder and the decoder to additional improve the options. Moreover, as a substitute of concatenating for the skip connections, the decoder implements addition, and the InstructIR mannequin implements solely the ICB or Instruction Conditioned Block for job routing solely in encoder and decoder. Shifting on, the InstructIR mannequin is optimized utilizing the loss between the restored picture, and the ground-truth clear picture, and the cross-entropy loss is used for intent classification head of the textual content encoder. The InstructIR mannequin makes use of the AdamW optimizer with a batch measurement of 32, and a studying fee of 5e-4 for practically 500 epochs, and in addition implements the cosine annealing studying fee decay. For the reason that picture mannequin within the InstructIR framework includes solely 16 million parameters, and there are solely 100 thousand realized textual content projection parameters, the InstructIR framework might be simply educated on normal GPUs, thus lowering the computational prices, and rising the applicability.
A number of Degradation Outcomes
For a number of degradations and multi-task restorations, the InstructIR framework defines two preliminary setups:
- 3D for three-degradation fashions to deal with degradation points like dehazing, denoising, and deraining.
- 5D for 5 degradation fashions to deal with degradation points like picture denoising, low gentle enhancements, dehazing, denoising, and deraining.
The efficiency of 5D fashions are demonstrated within the following desk, and compares it with state-of-the-art picture restoration and all-in-one fashions.

As it may be noticed, the InstructIR framework with a easy picture mannequin and simply 16 million parameters can deal with 5 completely different picture restoration duties efficiently due to the instruction-based steerage, and delivers aggressive outcomes. The next desk demonstrates the efficiency of the framework on 3D fashions, and the outcomes are corresponding to the above outcomes.

The primary spotlight of the InstructIR framework is instruction-based picture restoration, and the next determine demonstrates the unimaginable talents of the InstructIR mannequin to know a variety of directions for a given job. Additionally, for an adversarial instruction, the InstructIR mannequin performs an id that’s not pressured.

Ultimate Ideas
Picture restoration is a elementary drawback in pc imaginative and prescient because it goals to get better a high-quality clear picture from a picture that demonstrates degradations. In low-level pc imaginative and prescient, Degradations is a time period used to symbolize disagreeable results noticed inside a picture like movement blur, haze, noise, low dynamic vary, and extra. On this article, we’ve got talked about InstructIR, the world’s first picture restoration framework that goals to information the picture restoration mannequin utilizing human-written directions. For pure language prompts, the InstructIR mannequin can get better high-quality photos from their degraded counterparts and in addition takes into consideration a number of degradation sorts. The InstructIR framework is ready to ship state-of-the-art efficiency on a big selection of picture restoration duties together with picture deraining, denoising, dehazing, deblurring, and low-light picture enhancement.

